Cookiecutter for a more transparent and reproducible science
A few weeks back, I watched a tutorial called Data Science is Software from SciPy 2016. It reminded my about the debate how reproducible science really is. According to Nature, the majority of scientists agree that there is a reproducibility crisis.
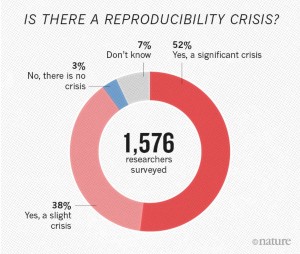
That is indeed frustrating, also because research itself should be transparent. I also understand why that is the case from my own experiences: Imagine you did some fine research and you’ve saved your results for a later publication. The results themselves have been hard to obtain, either beacuse of extensive data analysis, lenghty computer simultions or scraping data from a larger database. Later that year you realised that some of the results are corrupt or you did a mistake in the analysis or you had a wrong configuration. In this case you try to reproduce your own results. However, this is a tedious task, so you go back to the beginning a try to repeat each single step to get to your final result. Fine! But wait. Why not simply automating this process from the beginning? Yeah, sure, but how? Meet cookiecutter!
So I adopted the philosophy of the guys from the video above, which states that in order to deliver reproducible (data) science you need “A logical, reasonably standardized, but flexible project structure for doing and sharing data science work.”, and developed a similar cookiecutter project template aimed for scientists.
You can find the source on Github. Simply install it for your next science project:
cookiecutter gh:mkrapp/cookiecutter-reproducible-science
This tool provides you the basic structure of your research project. You can adjust it to your needsand need to fill it with your reproducible workflow. You can add a customized Makefile, add you preferred command line tools, scripts, or model source code. You can also add raw data and processed data. You can document and also write you scientific paper within this structure.
Let’s do more reproducible and transparent science!!!